n8n 中的 LangChain 概念#
本页解释了 LangChain 概念和功能如何映射到 n8n 节点。
本页包含 n8n 中专注于 LangChain 的节点列表。您可以在与 LangChain 交互的工作流中使用任何 n8n 节点,将 LangChain 与其他服务连接。LangChain 功能使用 n8n 的集群节点。
n8n 实现的是 LangChain JS
此功能是 n8n 对 LangChain 的 JavaScript 框架的实现。
触发器节点#
集群节点#
集群节点是指在工作流中协同工作以提供功能的节点组。不同于使用单一节点,您可以使用一个根节点和一个或多个子节点来扩展节点的功能。
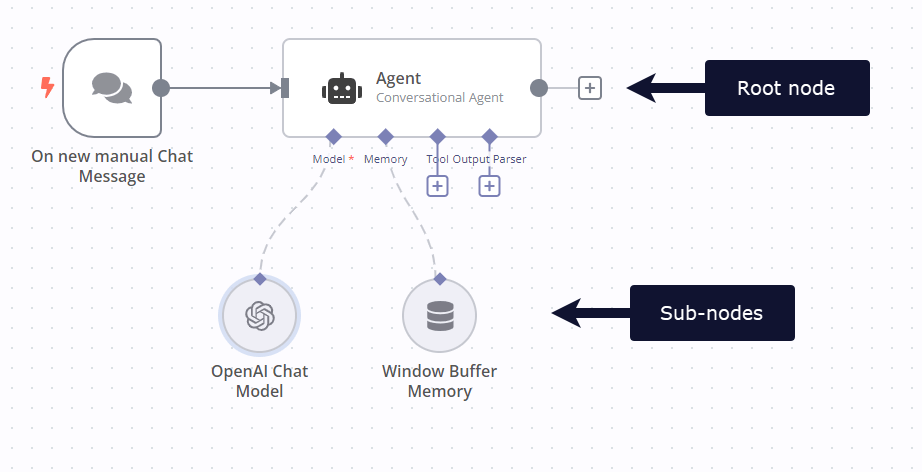
根节点#
每个集群以一个根节点开始。
链式结构#
链是由多个 LLM 和相关工具组成的序列,它们相互连接以支持单个 LLM 无法提供的功能。
可用节点:
了解更多关于 LangChain 中的链式结构。
代理(Agents)#
代理(Agent)可以访问一系列工具,并根据用户输入决定使用哪些工具。代理可以使用多个工具,并将一个工具的输出作为下一个工具的输入。来源
可用节点:
了解更多关于 LangChain中的代理。
向量存储(Vector stores)#
向量存储(Vector stores)存储嵌入数据,并对其执行向量搜索。
- 简单向量存储(Simple Vector Store)
- PGVector向量存储(PGVector Vector Store)
- Pinecone向量存储(Pinecone Vector Store)
- Qdrant向量存储(Qdrant Vector Store)
- Supabase向量存储(Supabase Vector Store)
- Zep向量存储(Zep Vector Store)
了解更多关于 LangChain中的向量存储。
其他功能#
实用工具节点。
LangChain代码(LangChain Code): 导入LangChain。这意味着如果n8n尚未创建您所需功能的节点,您仍然可以使用它。
子节点(Sub-nodes)#
每个根节点可以附加一个或多个子节点(Sub-nodes)。
文档加载器#
文档加载器将数据以文档形式添加到您的链中。数据源可以是文件或网络服务。
可用节点:
了解更多关于 LangChain 中的文档加载器。
语言模型#
LLMs (大语言模型) 是分析数据集的程序。它们是使用 AI 的关键组件。
可用节点:
- Anthropic 聊天模型
- AWS Bedrock 聊天模型
- Cohere 模型
- Hugging Face 推理模型
- Mistral Cloud 聊天模型
- Ollama 聊天模型
- Ollama 模型
- OpenAI 聊天模型
了解更多关于 LangChain 中的语言模型。
记忆功能#
记忆功能能够保留一系列查询中的历史信息。例如,当用户与聊天模型交互时,如果您的应用能够记住并调用完整的对话内容(而不仅仅是用户最近输入的查询),这将非常有用。
可用节点:
了解更多关于 LangChain 中的记忆功能。
输出解析器#
输出解析器接收大语言模型(LLM)生成的文本,并将其格式化为符合您需求的结构。
可用节点:
了解更多关于 LangChain 中的输出解析器。
检索器#
文本分割器#
文本分割器用于分解数据(文档),使大型语言模型(LLM)更容易处理信息并返回准确结果。
可用节点:
n8n的文本分割器节点实现了LangChain的text_splitter API的部分功能。
工具#
实用工具。
嵌入向量 (Embeddings)#
可用节点:
- AWS Bedrock 嵌入向量
- Cohere 嵌入向量
- Google PaLM 嵌入向量
- Hugging Face 推理嵌入向量
- Mistral Cloud 嵌入向量
- Ollama 嵌入向量
- OpenAI 嵌入向量
了解更多关于 LangChain 中的文本嵌入向量。